02 مارس 2016
دیدگاهها برای يادگيري چندبرچسبي و کاربرد در بيوانفورماتيک و دستهبندي متن بسته هستند
مسائل یادگیری چندبرچسبی در دنیای واقعی بسیار پرکاربرد هستند، به عنوان مثال در دستهبندی متن، هر سند ممکن است متعلق به چندین دستهی از قبل تعیین شده مثل سیاسی و سلامت باشد؛ در بیوانفورماتیک، هر ژن میتواند به چندین دستهی کاری مثل متابولیسم و سنتز پروتئین تعلق داشته باشد؛ در دستهبندی تصاویر، نیز هر تصویر ممکن است در چندین گروه ... ادامه مطلب »
02 مارس 2016
دیدگاهها برای يادگيري چندبرچسبي و کاربرد در بيوانفورماتيک و دستهبندي متن بسته هستند
یادگیری چندبرچسبی و کاربرد در بیوانفورماتیک و دستهبندی متن
ادامه مطلب »
18 فوریه 2016
دیدگاهها برای کلمات کلیدی مرتبط با دانلود مقاله، تحقیق، سمینار و پایان نامه- سری چهارم بسته هستند
کاربران اینترنت با جستجوی کلمات کلیدی زیر در موتورهای جستجو، به جامع ترین مرجع دانلود تحقیق، مقاله، سمینار و پایان نامه هدایت شده اند. در صورتیکه نیاز به هر کدام از مطالب مرتبط با کلمات کلیدی زیر دارید بر روی آن کلیک نمایید تا مطالب منتشر شده در جامع ترین مرجع دانلود تحقیق، مقاله، سمینار و پایان نامه مرتبط با ... ادامه مطلب »
11 فوریه 2016
دیدگاهها برای کلمات کلیدی مرتبط با پردازش متن، خلاصه سازی، ترجمه ماشینی بسته هستند
کاربران اینترنت با جستجوی کلمات کلیدی زیر در موتورهای جستجو، به جامع ترین مرجع دانلود تحقیق، مقاله، سمینار و پایان نامه هدایت شده اند. در صورتیکه نیاز به هر کدام از مطالب مرتبط با کلمات کلیدی زیر دارید بر روی آن کلیک نمایید تا مطالب منتشر شده در جامع ترین مرجع دانلود تحقیق، مقاله، سمینار و پایان نامه مرتبط با ... ادامه مطلب »
10 فوریه 2016
دیدگاهها برای کلمات کلیدی مرتبط با وب معنایی، آنتولوژی و پروتج بسته هستند
کاربران اینترنت با جستجوی کلمات کلیدی زیر در موتورهای جستجو، به جامع ترین مرجع دانلود تحقیق، مقاله، سمینار و پایان نامه هدایت شده اند. در صورتیکه نیاز به هر کدام از مطالب مرتبط با کلمات کلیدی زیر دارید بر روی آن کلیک نمایید تا مطالب منتشر شده در جامع ترین مرجع دانلود تحقیق، مقاله، سمینار و پایان نامه مرتبط با ... ادامه مطلب »
31 ژانویه 2016
204 نظرات
آنتولوژی در حقیقت آنتولوژی یکی از پایه های اصلی وب معنایی هست. همونطور که وب سنتی بر مبنای صفحات html بنا شده. وب معنایی نیز بر مبنای فایلهای متنی به نام انتولوژی است(فایلهایی با پسوند OWL).در این فایل متنی یک سری روابط خاص وجود داره. هر شی باید داخل یک کلاس جای بگیره.کلاس ها و زیر کلاسها به روش خاصی ... ادامه مطلب »
08 ژانویه 2016
دیدگاهها برای بازشناسی مبتنی بر ساختارهای تجمعی بسته هستند
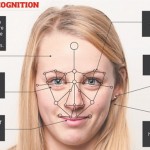
در این فصل، تعدادی از روش های بازشناسی چهره که از ساختارهای تجمعی استفاده می کنند، مورد بررسی قرار گیرند. بررسی این روش ها از یک سو ما را با کارهای انجام گرفته در این زمینه آشنا می کند. یک ساختار تجمعی، در حالت کلی چندین طبقه بند مستقل و یک مکانیزم جهت ترکیب نمودن خروجی این طبقه بندها می ... ادامه مطلب »
07 ژانویه 2016
دیدگاهها برای بازشناسی چهره مبتنی براختلاط خبره ها بسته هستند
گوناگونی روش ها از یکسو و عدم وجود یک روش که بتواند ادعا نماید در تمامی زمینه ها دارای بالاترین کارایی است، ما را به سمت ارائه روش های ترکیبی سوق داد. این روش ها می بایست به گونه ای طراحی گردند که هر روش بتواند نقاط قوت خود را حفظ نماید و از سوی دیگر در اثر تعامل روش ... ادامه مطلب »
05 ژانویه 2016
دیدگاهها برای بررسی چند روش بازشناسی مبتنی بر ساختارهای تجمعی بسته هستند
بررسی چند روش بازشناسی مبتنی بر ساختارهای تجمعی ادامه مطلب »
05 ژانویه 2016
دیدگاهها برای بازشناسی چهره مبتنی براختلاط خبره ها بسته هستند
بازشناسی چهره مبتنی براختلاط خبره ها ادامه مطلب »
05 ژانویه 2016
دیدگاهها برای الگوریتم های یادگیری تجمعی بسته هستند
الگوریتم های یادگیری تجمعی [Fre 1997, Mei 2003, Hay 1998] که ماشین های مشاور نیز نامیده می شوند، یک دسته از الگوریتم های یادگیری به شیوه با سرپرست هستند. این روش ها از تقسیم و حل استفاده می کنند. در روش های مبتنی بر تقسیم و حل یک کار بزرگ به تعدادی کار کوچک شکسته می شود. سپس هر کار ... ادامه مطلب »
05 ژانویه 2016
دیدگاهها برای الگوریتم های یادگیری تجمعی بسته هستند
الگوریتم های یادگیری تجمعی ادامه مطلب »
31 دسامبر 2015
دیدگاهها برای فااسپل: ﺩﺍﺩﻩ ﺍﺭﺯﯾﺎﺑﯽ خطایابهای املایی بسته هستند
کد داده: D3940825a | ثبت در مرجع: ۲۵ آبان ۱۳۹۴ | تعداد بازدید: ۲۸۰ «فااسپل» متشکل از دو ﻣﺠﻤﻮﻋﻪ ﺩﺍﺩﻩ ﺑﺮﺍی ﺍﺭﺯﯾﺎﺑﯽ ﺭوﺵهای خطایابی املایی است. گروه اول شامل خطاهای معمول است که از دانشآموزان مدارس و همچنین خطاهای املایی در هنگام تایپ فارسی جمعآوری شدهاند. این گروه شامل ۵۵۰۰ خطا و کلمهٔ تصحیحشده است. گروه دوم شامل ۸۰۰ جفت ... ادامه مطلب »
23 دسامبر 2015
دیدگاهها برای دامنه ی ir یا com؟ بسته هستند
به طور معمول برندها برای ثبت دامنه از پسوندهای org,net,co و… استفاده نمی کنند. در کشور ما پسوندهای ir و com رایج ترین پسوندهایی هستند که برای سایت برندها مورد استفاده قرار میگیرد؛ حال سوال اینجاست که com بهتر است یا ir؟ ممکن است هر دو پسوند را برای سایت یک برند ثبت کرده و مورد استفاده قرار دهیم اما ... ادامه مطلب »
16 دسامبر 2015
دیدگاهها برای پیکره فارسی ارزیابی سامانههای تقلبیاب بسته هستند
کد داده: D3940531a | ثبت در مرجع: ۳۱ مرداد ۱۳۹۴ | تعداد بازدید: ۲۹۵ پیکره حاضر که با هدف ارزیابی سامانههای تقلبیاب تهیه شده است مشتمل بر بیش از ۱۵۰۰ سند فارسی از ویکیپدیا است که ۴۱۱ نمونه تقلب در آنها گنجانده شده است. در قسمتهای حاوی تقلب فرایندهایی چون جابجایی کلمات، حذف و اضافه نمودن کلمات و جایگزین نمودن ... ادامه مطلب »
15 دسامبر 2015
دیدگاهها برای پیکره فارسی تحلیل احساس سِنتیپِرس بسته هستند
کد داده: D3940423a | ثبت در مرجع: ۲۴ تیر ۱۳۹۴ | تعداد بازدید: ۶۰۲ پیکره سِنتیپِرس شامل مجموعهای از جملات فارسی با برچسبهای حاوی بار معنایی است که در پردازش زبان طبیعی و به طور مشخص در زمینه تحلیل احساس یا عقیدهکاوی کاربرد دارد. با توجه به ویژگیهای این پیکره، میتوان آن را در نوع خود اولین پیکره تحلیل احساس ... ادامه مطلب »