مقالات فارسی پردازش زبان طبیعی NLP متن کاوی زبان فارسی ادامه مطلب »
مقالات فارسی پردازش زبان طبیعی NLP

مقالات فارسی پردازش زبان طبیعی NLP متن کاوی زبان فارسی ادامه مطلب »

با گسترش روزافزون حجم اطلاعات موجود در وب و افزايش چشم گير مقالات منتشر شده در زمينه هاي مختلف علمي ، دسترسي درست و مطالعه اطلاعات مورد نياز، همواره يکي از مشکلات محققان و پژوهشگران قرن 21 مي باشد. اينکه چه طور از يک طرف با اين حجم انبوه از داده ها و از طرفي ديگر با زمان محدودي که ... ادامه مطلب »
خلاصه سازي, خودکار, سند, مبتني بر کاربر, ماشینی,انسانی,ارزیابی, چکیده, استخراجی ادامه مطلب »

طراحی یک سیستم توصیه گر ترکیبی معنایی با استفاده از تکنیکهای پردازش زبان طبیعی فارسی ادامه مطلب »

معیارهای ارزیابی سیستم های توصیه گر ادامه مطلب »

معرفي دو ابزار توليد تحليلگر لغوي و تحليلگر نحوي از هنگامي كه تحليگر هاي لغوي و تجزيه كننده ها با دست نوشته مي شدند ، ]كم كم و ناخودآگاه[ تحليلگرهاي لغوي و تجزيه-كننده ها به طراحي يكساني رسيدند و طراحان فهميدند كه آنها را مي توان با دادن شرحي از رفتار مورد نظرشان ، به طور خودكار توليد كرد . ... ادامه مطلب »
ابزارهای مولد تحليلگر لغوي و تحليلگر نحوي Lex و Yacc ادامه مطلب »
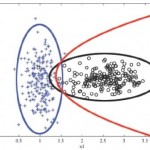
توجه شود که در يک مسئله دستهبندي ابتدا بايد هر سند موجود در مجموعه آموزشي داده شده را در متغير مناسبي ذخيره کرد و نام دسته آن سند را که با مشخصه اي خاص مثلا نام سند بدست آورد و سپس تمام توکنهاي سند استخراج و در محل مناسبي ذخيره گردد .حال کلمات توقف را حذف ميشود. چون اين کلمات ... ادامه مطلب »
دسته بندی متن با استفاده از تئوری بیز ادامه مطلب »
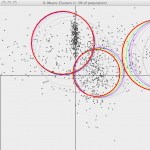
دستهبندي متن شامل نسبت دادن اسناد به يکي از چند گروه از پيش تعيين شده است. براي نايل شدن به اين هدف اسناد ورودي توسط يک مجموعه از مشخصات[1] که معمولاً خصوصيات[2] ناميده ميشود توصيف ميشوند. برخلاف خوشهبندي[3] که شامل آموزش بدون نظارت است، در دستهبندي يک مجموعه آموزشي از دادهها با برچسبگذاري قبلي نياز است (يادگيري ماشين نظارتي). هدف ... ادامه مطلب »
دسته کننده K نزديکترين مجاور ادامه مطلب »

دستهبندي متن شامل نسبت دادن اسناد به يکي از چند گروه از پيش تعيين شده است. براي نايل شدن به اين هدف اسناد ورودي توسط يک مجموعه از مشخصات[1] که معمولاً خصوصيات[2] ناميده ميشود توصيف ميشوند. برخلاف خوشهبندي[3] که شامل آموزش بدون نظارت است، در دستهبندي يک مجموعه آموزشي از دادهها با برچسبگذاري قبلي نياز است (يادگيري ماشين نظارتي). هدف ... ادامه مطلب »
دسته بندی متن با استفاده از درخت تصمیم ادامه مطلب »
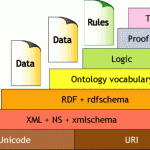
وب معنایی – فصل اول: مأموریت وب معنایی Semantic Web Primer (2nd Edition) Chapter 1: Sementic Web Vision فصل اول: مأموریت وب معنایی قالب فایل: Word تعداد صفحات: 15 صفحه مشاهده جزئیات بیشتر http://www.tnt3.ir/downloads/semanti_web_chapter-1 وب معنایی – فصل دوم: اسناد ساخت یافته وب XML Semantic Web Primer (2nd Edition) Chapter 2: Structured Web Documents: XML فصل دوم: اسناد ... ادامه مطلب »
وب معنایی , فرهنگ لغت, Glossary ادامه مطلب »
Conclusion and Outlook Semantic Web نتیجه گیری و چشم انداز آینده وب معنایی ادامه مطلب »
