حفظ حريم خصوصی, کاوش سودمندي, کاوش قوانين انجمني, داده کاوي, برنامه ریزی عدد صحیح, الگوریتم های مکاشفه ای, الگوریتم های تکاملی ادامه مطلب »
مخفی سازی قوانین انجمنی و حفظ حریم خصوصی

حفظ حريم خصوصی, کاوش سودمندي, کاوش قوانين انجمني, داده کاوي, برنامه ریزی عدد صحیح, الگوریتم های مکاشفه ای, الگوریتم های تکاملی ادامه مطلب »

1. كشف سرقت ادبی در متون فارسی با كمك الگوریتم SimHash خلاصه مقاله: دسترسی آسان به وب، پایگاه داده های بزرگ و به طور كلی ارتباطات از راه دور باعث شده كه سرقت ادبی به یك مشكل بزرگ برای ناشران، محققان و موسسات آموزشی تبدیل شود. در زبان انگلیسی این مسئله به طور جدی مورد اهمیت بوده و ابزارهای ... ادامه مطلب »
سرقت ادبی , اثر انگشت , فاصله همینگ , shingling , simHash , بازیابی متن , تشخیص سرقت علمی , ادبی بیرونی , سرقت علمی , ادبی , شباهت متون , تشخیص سرقت علمی , اخلاق در پژوهش , جعل پیشینه , سرقت ادبی , انتحال , پلاگاریسم , تشخیص پلاگاریستم متن دو زبانه , تحلیل شباهت , تحلیل مورفولوژیك , مدل فضای برداری (vsm) , تشخیص پلاگاریسم دوزبانه , تحلیل محتوی , تحلیل اطلاعات آماری , بازیابی اطلاعات , شباهت متون , یادگیری ماشین , دسته بندی متون , طبقه بندی متون , پردازش زبان های طبیعی , هستانشناسی , طبقهبندی , تشابه معنایی , وبمعنایی , همرخدادی , ترجمه ماشینی , روش های نظارت شده , فاصله اقلیدسی , شباهت cosine , طبقه بند مبتنی بر یادگیری جمعی , خوشه بندی , معیار شباهت فازی , اثرانگشت , RareChunk , SPEX , winnowing , بازیابی اطلاعات , تشابه متن , ریخت شناسی , وندها , زبان فارسی ادامه مطلب »
در این پایاننامه، یک روش مبتنی بر خوشهبندی برای خلاصهسازی چندسندی متون پیشنهاد شده است. یک سامانهی خلاصهسازی گزینشی چندسندی، خلاصهسازی است که چند سند را به عنوان ورودی میگیرد و خلاصهای تولید میکند که گزیدهای از جملههای سندهای اولیه است. اگر چه روش پیشنهادی محدود به حوزه نیست، اما ارزیابی آن روی یک مجموعه از خبرهای ورزشی فارسی صورت ... ادامه مطلب »

ردیف موضوع قالب فایل عنوان فایل کلمات کلیدی متن 1 شبکه های کامپیوتری پی دی اف GSM زیرسیستم های شبکه GSM، زیر سیستم رادیو، خدکات شبکه GSM، هویت MS در شبکه GSM ، توضیحات MSC و BSC 2 شبکه های کامپیوتری پاور پوئینت مخابرات سلولی واستاندارد ان درا یران GSM تلفن های سلولی انا لوگ، برقراری یک ارتباط توسط تلفن ... ادامه مطلب »

85 بررسی و ارائه سه روش اساسی جهت نهان نگاری در متون 154 نهان نگاری داده های فارسی در تصاویر پزشکی با قابیلت ظرفیت بالا 177 پنهان نگاری در زبان فارسی با استفاده از افزونگی های خط نستعلیق 178 پنهان نگاری در خط تحریری با استفاده از کشیده نویسی برخی حروف 206 پنهان نگاری در متون فارسی بوسیله الگوریتم رمزنگاری ... ادامه مطلب »
174 نویسه گردانی اسامی افراد با استفاده از ویژگی های محتوای وب فارسی 175 طراحی ریشه یاب معنایی فارسی 182 بهبود الگوریتم بهینه ساز جمعیت مورچگان باینری برای مساله انتخاب ویژگی با استفاده از روش های کلاسیک انتخاب پیشرو و حذف پسرو 184 طراحی ابزار پارسر زبان فارسی 185 طراحی یک سیستم توصیه گر ترکیبی معنایی با استفاده از تکنیک ... ادامه مطلب »

در این قسمت تعدادی مقاله فارسی در مورد پردازش زبان طبیعی زبان فارسی با موضوعات زیر ارائه می گردد: تمام فایل ها به صورت پی دی اف و در قالب مقاله کنفرانسی می باشد. مقالات دارای بخشهای متداول در تمامی مقالات کنفرانسی شامل چکیده، مقدمه، کارهای انجام شده، روش پیشنهادی ، ارزیابی و نتیجه گیری می باشد. (با ذکر تمامی منابع ... ادامه مطلب »
در این قسمت 58 مقاله فارسی در مورد پردازش زبان طبیعی زبان فارسی با موضوعات زیر ارائه می گردد: 1 طراحی و پیاده سازی یک سامانه ترجمه فارسی به انگلیسی 2 بازشناسی حروف برخط فارسی با استفاده از مدل مخفی مارکوف 3 آنالیز احساسی متون فارسی 4 بررسی ویژگی های وابسته به فرکانس پایه لهجه های مختلف زبان فارسی 5 ... ادامه مطلب »
مقالات فارسی پردازش زبان طبیعی NLP متن کاوی زبان فارسی ادامه مطلب »
دانلود کد آماده ریشه یابی در زبان فارسی - الگوریتم ریشه یابی فارسی - persian stemmer ادامه مطلب »

الگوریتم های بکار رفته در سیستم های توصیه گر, مفاهیم موجود در سیستم های توصیه گر , توضیح انواع سیستم های توصیه گر ادامه مطلب »

معیارهای ارزیابی سیستم های توصیه گر ادامه مطلب »
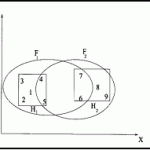
دستهبندي متن شامل نسبت دادن اسناد به يکي از چند گروه از پيش تعيين شده است. براي نايل شدن به اين هدف اسناد ورودي توسط يک مجموعه از مشخصات[1] که معمولاً خصوصيات[2] ناميده ميشود توصيف ميشوند. برخلاف خوشهبندي[3] که شامل آموزش بدون نظارت است، در دستهبندي يک مجموعه آموزشي از دادهها با برچسبگذاري قبلي نياز است (يادگيري ماشين نظارتي). هدف ... ادامه مطلب »
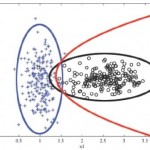
توجه شود که در يک مسئله دستهبندي ابتدا بايد هر سند موجود در مجموعه آموزشي داده شده را در متغير مناسبي ذخيره کرد و نام دسته آن سند را که با مشخصه اي خاص مثلا نام سند بدست آورد و سپس تمام توکنهاي سند استخراج و در محل مناسبي ذخيره گردد .حال کلمات توقف را حذف ميشود. چون اين کلمات ... ادامه مطلب »
دستهبندي متن شامل نسبت دادن اسناد به يکي از چند گروه از پيش تعيين شده است. براي نايل شدن به اين هدف اسناد ورودي توسط يک مجموعه از مشخصات[1] که معمولاً خصوصيات[2] ناميده ميشود توصيف ميشوند. برخلاف خوشهبندي[3] که شامل آموزش بدون نظارت است، در دستهبندي يک مجموعه آموزشي از دادهها با برچسبگذاري قبلي نياز است (يادگيري ماشين نظارتي). هدف ... ادامه مطلب »
