نخستین شبكه ی واژگان زبان فارسی تحت عنوان فارسنت (وردنت عمومی زبان فارسی) با حمایت مرکز تحقیقات مخابرات ایران در پژوهشكدهی IT پژوهشگاه فضای مجازی و با همكاری متخصصان از هر دو حوزهی رایانه و زبان شناسی دانشگاه شهید بهشتی تهیه گردیده است. در واقع هدف ایجاد فارسنت، ايجاد يک شاخهی فارسي براي Word Net است که در تحقيقات و پژوهشهاي زبان فارسي قابل استفاده باشد ... ادامه مطلب »
خانه -> نتیجه جستجو برای : زبان فارسی (برگه 6)
نتیجه جستجو برای : زبان فارسی
شبکه واژگان فارسی، فارس نت و فردوس نت
نخستین شبكه ی واژگان زبان فارسی تحت عنوان فارسنت (وردنت عمومی زبان فارسی) با حمایت مرکز تحقیقات مخابرات ایران در پژوهشكدهی IT پژوهشگاه فضای مجازی و با همكاری متخصصان از هر دو حوزهی رایانه و زبان شناسی دانشگاه شهید بهشتی تهیه گردیده است. در واقع هدف ایجاد فارسنت، ايجاد يک شاخهی فارسي براي Word Net است که در تحقيقات و پژوهشهاي زبان فارسي قابل استفاده باشد ... ادامه مطلب »
کد استفاده از کتابخانه های ابزارهای پردازش متن فارسی
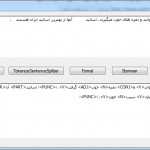
کد استفاده از کتابخانه های ابزارهای پردازش متن فارسی در این کد که به زبان سی شارپ نوشته شده است چگونگی استفاده از کتابخانه های ابزارهای پردازش متن فارسی زیر آورده شده است: – نرمالسازی متون فارسی – Normalizer – تشخیص جملات – Sentence Spliter – تشخیص کلمات – Tokenizer – ریشه یابی کلمات – Stemmer – برچسب زنی نحوی کلمات ... ادامه مطلب »
کد استفاده از کتابخانه های ابزارهای پردازش متن فارسی
کد استفاده از کتابخانه های ابزارهای پردازش متن فارسی ادامه مطلب »
نوشتن PLUGIN فارسی برای نرم افزار پردازش متن GATE

GATE یک نرم افزار پردازش متن است که توسط تیم طراحی دانشگاه Sheffield ساخته شده است. پردازشی که توسط این نرم افزار صورت می گیرد براساس اجزاء موجود در آن، به صورت ترتیبی، صورت می گیرد. لذا قابلیت این وجود دارد که بخش های مختلف توسط کاربران و برنامه نویسان توسعه یابد و بعنوان یک جزء جدا به آن اضافه ... ادامه مطلب »
نوشتن PLUGIN فارسی برای نرم افزار پردازش متن GATE
نوشتن PLUGIN فارسی برای نرم افزار پردازش متن GATE ادامه مطلب »
گزارش دوره آموزش سریع میکروکنترلر AVR به زبان ساده

گزارش دوره آموزشی AVR به زبان ساده ادامه مطلب »
خلاصه ساز خودكار متون فارسی – روش ها و الگوریتم ها

مقاله اول: خلاصه سازي متون فارسي با استفاده از هستي شناسي و خوشه بندي خلاصه مقاله: يكي از مشكلات اصلي در تحقيق روي خلاصه سازي خودكار، تفسير معنايي نادرست از سند است. استفاده از دامنه دانش منحصر بفرد مي تواند اين مشكل را به طور قابل توجهي كم كند. در اين مقاله ما يك روش استخراجي مبتني بر هستي شناسي ... ادامه مطلب »
خلاصه ساز خودكار متن فارسی – روش ها و الگوریتم ها
خلاصه ساز خودكار متن فارسی - روش ها و الگوریتم ها ادامه مطلب »
چگونگی محاسبه میزان تشابه معنایی مقالات برای متون زبان انگلیسی

چگونگی محاسبه میزان تشابه معنایی مقالات برای متون زبان انگلیسی در نخستین گام از طراحی و پیادهسازی ابزار مورد نظر برای محاسبه میزان تشابه متون، بایستی بسیاری از ابزارهای پایهای پردازش زبان انگلیسی از ابتدا و با رویکردی اصولی منطبق بر قواعد گرامری و نگارشی زبان انگلیسی طراحی و پیادهسازی گردد. از جملهی این ابزارها میتوان ابزار نرمالساز یا یکسانساز، ... ادامه مطلب »
چگونگی محاسبه میزان تشابه معنایی مقالات برای متون زبان انگلیسی
چگونگی محاسبه میزان تشابه معنایی مقالات برای متون زبان انگلیسی ادامه مطلب »
خلاصهسازی گزینشی چندسندی متون فارسی
در این پایاننامه، یک روش مبتنی بر خوشهبندی برای خلاصهسازی چندسندی متون پیشنهاد شده است. یک سامانهی خلاصهسازی گزینشی چندسندی، خلاصهسازی است که چند سند را به عنوان ورودی میگیرد و خلاصهای تولید میکند که گزیدهای از جملههای سندهای اولیه است. اگر چه روش پیشنهادی محدود به حوزه نیست، اما ارزیابی آن روی یک مجموعه از خبرهای ورزشی فارسی صورت ... ادامه مطلب »
خلاصهسازی گزینشی چندسندی متون فارسی
خلاصهسازي گزينشي چندسندي متون فارسي یك روش آماری مبتنی بر پیكره برای جداسازی واژه های به هم چسبیده بازیابی خبرهای مرتبط پیشین برای تولید خلاصه های پیشینه-خبر استخراج بردارهای همبستگی واژه های فارسی در یك پیكره متنی بزرگ از اخبار خلاصه سازی چند سندی متون فارسی با استفاده از یك روش مبتنی بر خوشه بندی اخبار فارسی برای تولید خلاصه های پیشینه-خبر ادامه مطلب »
كشف سرقت ادبی – تشخیص پلاگاریسم (Plagiarism)

سرقت ادبی , اثر انگشت , فاصله همینگ , shingling , simHash , بازیابی متن , تشخیص سرقت علمی , ادبی بیرونی , سرقت علمی , ادبی , شباهت متون , تشخیص سرقت علمی , اخلاق در پژوهش , جعل پیشینه , سرقت ادبی , انتحال , پلاگاریسم , تشخیص پلاگاریستم متن دو زبانه , تحلیل شباهت , تحلیل مورفولوژیك , مدل فضای برداری (vsm) , تشخیص پلاگاریسم دوزبانه , تحلیل محتوی , تحلیل اطلاعات آماری , بازیابی اطلاعات , شباهت متون , یادگیری ماشین , دسته بندی متون , طبقه بندی متون , پردازش زبان های طبیعی , هستانشناسی , طبقهبندی , تشابه معنایی , وبمعنایی , همرخدادی , ترجمه ماشینی , روش های نظارت شده , فاصله اقلیدسی , شباهت cosine , طبقه بند مبتنی بر یادگیری جمعی , خوشه بندی , معیار شباهت فازی , اثرانگشت , RareChunk , SPEX , winnowing , بازیابی اطلاعات , تشابه متن , ریخت شناسی , وندها , زبان فارسی ادامه مطلب »
فاکتورهای موثر در افزایش رتبه سایت در موتور جستجوی گوگل

در این مقاله قصد داریم آخرین و جدیدترین عوامل موثر در افزایش جایگاه سایت ها در موتور جستجوی گوگل که در واقع به سئوی سایت ها کمک می کند را بررسی نماییم. فاکتورهای موثر در رتبه گوگل بر طبق یک میلیون نتیجۀ جستجو هیچ شکی نیست که تمام کسانی که در فضای آنلاین فعال هستند، میخواهند بدانند که کدام عوامل و فاکتورهای سئو ... ادامه مطلب »
مجموعه داده استاندارد وبلاگهای ایران

کد داده: D3941014a | ثبت در مرجع: ۱۵ دی ۱۳۹۴ | تعداد بازدید: ۲۱۷۵ مجموعه داده استاندارد وبلاگهای ایران (irBlogs) جهت ایجاد بستری مناسب برای تحقیق و ارائهٔ الگوریتم در زمینهٔ شبکههای اجتماعی ایرانی تولید شده است. این مجموعه شامل متون برگرفته از بیش از ۶۰۰ هزار وبلاگ (نزدیک به ۵ میلیون پست) است و گراف روابط افراد نیز برای ... ادامه مطلب »
