11 فوریه 2016
دیدگاهها برای کلمات کلیدی مرتبط با پردازش متن، خلاصه سازی، ترجمه ماشینی بسته هستند
کاربران اینترنت با جستجوی کلمات کلیدی زیر در موتورهای جستجو، به جامع ترین مرجع دانلود تحقیق، مقاله، سمینار و پایان نامه هدایت شده اند. در صورتیکه نیاز به هر کدام از مطالب مرتبط با کلمات کلیدی زیر دارید بر روی آن کلیک نمایید تا مطالب منتشر شده در جامع ترین مرجع دانلود تحقیق، مقاله، سمینار و پایان نامه مرتبط با ... ادامه مطلب »
08 ژانویه 2016
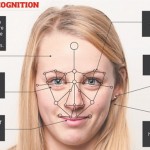
دیدگاهها برای بازشناسی مبتنی بر ساختارهای تجمعی بسته هستند
در این فصل، تعدادی از روش های بازشناسی چهره که از ساختارهای تجمعی استفاده می کنند، مورد بررسی قرار گیرند. بررسی این روش ها از یک سو ما را با کارهای انجام گرفته در این زمینه آشنا می کند. یک ساختار تجمعی، در حالت کلی چندین طبقه بند مستقل و یک مکانیزم جهت ترکیب نمودن خروجی این طبقه بندها می ... ادامه مطلب »
07 ژانویه 2016
دیدگاهها برای بازشناسی چهره مبتنی براختلاط خبره ها بسته هستند
گوناگونی روش ها از یکسو و عدم وجود یک روش که بتواند ادعا نماید در تمامی زمینه ها دارای بالاترین کارایی است، ما را به سمت ارائه روش های ترکیبی سوق داد. این روش ها می بایست به گونه ای طراحی گردند که هر روش بتواند نقاط قوت خود را حفظ نماید و از سوی دیگر در اثر تعامل روش ... ادامه مطلب »
05 ژانویه 2016
دیدگاهها برای بررسی چند روش بازشناسی مبتنی بر ساختارهای تجمعی بسته هستند
بررسی چند روش بازشناسی مبتنی بر ساختارهای تجمعی ادامه مطلب »
05 ژانویه 2016
دیدگاهها برای بازشناسی چهره مبتنی براختلاط خبره ها بسته هستند
بازشناسی چهره مبتنی براختلاط خبره ها ادامه مطلب »
05 ژانویه 2016
دیدگاهها برای الگوریتم های یادگیری تجمعی بسته هستند
الگوریتم های یادگیری تجمعی [Fre 1997, Mei 2003, Hay 1998] که ماشین های مشاور نیز نامیده می شوند، یک دسته از الگوریتم های یادگیری به شیوه با سرپرست هستند. این روش ها از تقسیم و حل استفاده می کنند. در روش های مبتنی بر تقسیم و حل یک کار بزرگ به تعدادی کار کوچک شکسته می شود. سپس هر کار ... ادامه مطلب »
05 ژانویه 2016
دیدگاهها برای الگوریتم های یادگیری تجمعی بسته هستند
الگوریتم های یادگیری تجمعی ادامه مطلب »
31 دسامبر 2015
دیدگاهها برای فااسپل: ﺩﺍﺩﻩ ﺍﺭﺯﯾﺎﺑﯽ خطایابهای املایی بسته هستند
کد داده: D3940825a | ثبت در مرجع: ۲۵ آبان ۱۳۹۴ | تعداد بازدید: ۲۸۰ «فااسپل» متشکل از دو ﻣﺠﻤﻮﻋﻪ ﺩﺍﺩﻩ ﺑﺮﺍی ﺍﺭﺯﯾﺎﺑﯽ ﺭوﺵهای خطایابی املایی است. گروه اول شامل خطاهای معمول است که از دانشآموزان مدارس و همچنین خطاهای املایی در هنگام تایپ فارسی جمعآوری شدهاند. این گروه شامل ۵۵۰۰ خطا و کلمهٔ تصحیحشده است. گروه دوم شامل ۸۰۰ جفت ... ادامه مطلب »
23 دسامبر 2015
دیدگاهها برای دامنه ی ir یا com؟ بسته هستند
به طور معمول برندها برای ثبت دامنه از پسوندهای org,net,co و… استفاده نمی کنند. در کشور ما پسوندهای ir و com رایج ترین پسوندهایی هستند که برای سایت برندها مورد استفاده قرار میگیرد؛ حال سوال اینجاست که com بهتر است یا ir؟ ممکن است هر دو پسوند را برای سایت یک برند ثبت کرده و مورد استفاده قرار دهیم اما ... ادامه مطلب »
14 دسامبر 2015
دیدگاهها برای پیکره – پی.سی.ای.سی ۲۰۰۸ (پیکره مرجع ضمیر) بسته هستند
کد داده: D3940406a | ثبت در مرجع: ۰۶ تیر ۱۳۹۴ | تعداد بازدید: ۶۲۹ پیکره پی.سی.ای.سی ۲۰۰۸ (PCAC-2008 Persian Coreferentially Annotated Corpus) مجموعهای است شامل ۳۱ متن برگرفته از پیکره بیجنخان که در آن نزدیکترین مرجع اسمی ۲۰۷۹ ضمیر مشخص شده است. دسترسی به اطلاعات مربوط به مرجع ضمیر در بسیاری از کاربردهای پردازش زبان طبیعی چون ترجمه ماشینی، پرسش ... ادامه مطلب »
08 دسامبر 2015
دیدگاهها برای پیکره – دادگان تلفنی اعداد متصل بسته هستند
کد داده: D3930414a | ثبت در مرجع: ۱۵ تیر ۱۳۹۳ | تعداد بازدید: ۲۱۸۸ دادگان تلفنی اعداد متصل زبان فارسی شامل دادههای ضبطشده تلفنی از اعداد فارسی به صورت متصل است و مشتمل بر ۱۱۰ گوینده میباشد كه هر یك تقریبا ۷۰ رشته عددی را بیان كردهاند. هر رشته عددی جداگانه بر چسبدهی شده است. آزمایشهای متنوعی كه به وسیله ... ادامه مطلب »
02 دسامبر 2015
33 نظرات
کد داده: D3920916a | ثبت در مرجع: ۱۶ آذر ۱۳۹۲ | تعداد بازدید: ۲۳۷۴ پیکره بیجنخانی مجموعهای است از متون فارسی شامل بیش از ۲میلیون و ۶۰۰هزار کلمه که با ۵۵۰ نوع برچسب POS برچسبگذاری شدهاند. این پیکره که در پژوهشکده پردازش هوشمند علائم تهیه شده است همچنین شامل بیش از ۴۳۰۰ تگ موضوعی چون سیاسی، تاریخی و … برای ... ادامه مطلب »
01 دسامبر 2015
دیدگاهها برای پیکره نور [منتشر نشده] بسته هستند
کد داده: D3920811a | ثبت در مرجع: ۱۱ آبان ۱۳۹۲ | تعداد بازدید: ۱۷۳۵ پیکره نور مجموعهای است عظیم از متون اسلامی که عمدتاً به زبان عربی و فارسی نوشته شدهاند. متون مربوط به بیش از ۴ هزار کتاب عربی (بیش از یک میلیارد کلمه) و بیش از ۲ هزار کتاب فارسی (بیش از ۶۰۰ میلیون کلمه) و همچنین بالغ ... ادامه مطلب »
26 نوامبر 2015
دیدگاهها برای پیکره – مجموعه ارقام دستنویس هدی بسته هستند
کد داده: D3920411a | ثبت در مرجع: ۱۷ تیر ۱۳۹۲ | تعداد بازدید: ۱۹۸۲ مجموعه ارقام دستنویس هدی مجموعه بزرگی از ارقام دستنویس فارسی است که مشتمل بر ۱۰۲۳۵۳ نمونه دستنوشته سیاه سفید میباشد. این مجموعه طی انجام یک پروژه کارشناسی ارشد در دانشگاه تربیت مدرس برای بازشناسی فرمهای دستنویس تهیه شده است. دادههای این مجموعه از حدود ۱۲۰۰۰ فرم ثبت ... ادامه مطلب »
24 نوامبر 2015
75 نظرات
کد داده: D3920326a | ثبت در مرجع: ۲۹ خرداد ۱۳۹۲ | تعداد بازدید: ۲۰۱۴ پیکره متنی و زیرساختی که تحت عنوان «پیکره فرقان» برای قرآن کریم تولید گردیده است، حاصل بهرهگیری از سامانهای هوشمند است که در آزمایشگاه فناوری وب دانشگاه فردوسی مشهد، طراحی و پیادهسازی شده است. این پیکره با بیش از 587 مگابایت داده، حاوی کلیه اطلاعات قرآنی، ... ادامه مطلب »
21 نوامبر 2015
دیدگاهها برای پیکره – تنزیل (پیکره قرآنی) بسته هستند
کد داده: D3920228a | ثبت در مرجع: ۲۸ اردیبهشت ۱۳۹۲ | تعداد بازدید: ۱۵۳۸ تنزیل یک پروژه بینالمللی قرآنی است که با هدف فراهمسازی نسخهای دقیق از قرآن کریم ایجاد شده است. در این پروژه علاوه بر ارائه نسخه رقومی دقیقی از متن قرآن، بالغ بر ۱۰۰ ترجمه از قرآن کریم برای بیش از ۴۰ زبان دنیا از جمله ۱۱ ... ادامه مطلب »