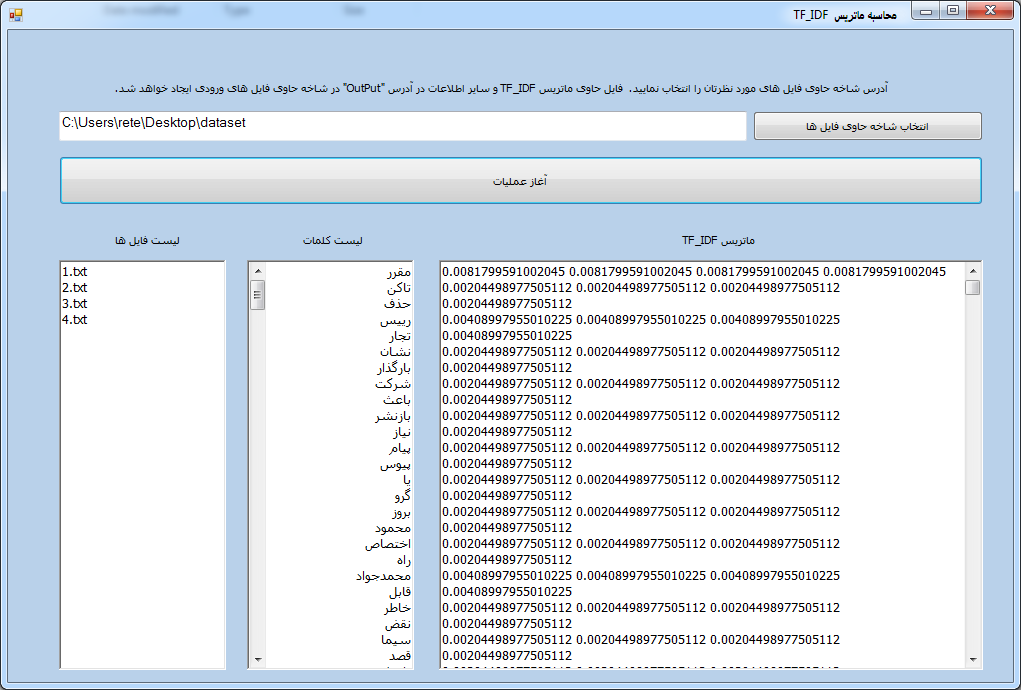
الگوریتم و کد آماده سی شارپ TF-IDF
فراوانی وزنی تیاف-آیدیاف (به انگلیسی: tf–idf weight) مخفف فراوانی – عکس فراوانی سند است. در این شیوه به لغات یک وزن بر اساس فراوانی آن در سند داده میشود. در واقع این سیستم وزن دهی نشان میدهد چقدر یک کلمه برای یک سند (مدرک) مهم است. این مسئله کاربردهای بسیاری در بازیابی اطلاعات دارد. وزن کلمه با افزایش تعداد تکرار آن در متن افزایش مییابد، اما توسط تعداد کلمات در متن کنترل میشود، چرا که میدانیم در صورت زیاد بودن طول متن، بعضی از کلمات به طول طبیعی بیشتر از دیگران تکرار خواهند شد، اگرچه چندان اهمیتی در معنی نداشته باشند.
اگر فرض کنیم تعداد دفعاتی که کلمه T در متن D اتفاق افتاده با (Tf (t.d نشان داده شود و در سادهترین حالت تعداد تکرار اولیه t با (f(t,d نشان داده شود پس
tf(t,d)= f(t,d).
موارد دیگر در زیر آمده
- بولین فراوانی:
tf(t,d)=
اگر کلمه t در متن اتفاق افتاده باشد مقدار 1 و در غیر اینصورت مقدار 0
- امتیاز دهی فراوانی لگاریتمی:
log (f(t,d)+1) tf(t,d)=
- فراوانی تکمیل شده، augmented frequency برای جلوگیری از بایاس به سمت متون بزرگتر (یعنی به دلیل حجم بالاتر متن نسبت به دیگری ممکنه کلمه مورد نظر بیشتر تکرار شده باشد ولی این به دلیل فراوانی بیشتر کلمه در متن بزرگتر نیست). به عنوان مثال فراوانی اولیه کلمه t تقسیم بر تعداد فراوانی اولیه هر کلمهای که در متن بیشترین فراوانی را دارد. این مورد بیشتر در موتور جستجو برای بازیابی مستندات با کلمات مورد جستجو استفاده دارد.
tf(f,d)=0.5+(0.5*f(t,d))/max{f(w,d):w∈d}
Idf: معیاری است برای میزان کلماتی که در کلیه متون بسیار متداول هستند و معمولاً تکرار میشوند. طریقه بدست آورن این معیار بدین صورت است که از لگاریتم، تقسیم تعداد کل متون بر تعداد متون شامل کلمه متداول بدست میآید. برای مثال: فرض کنیم در کل پایگاه داده ما ۱۰۰۰ تا متن وجود داشته باشد. اگر در هر ۱۰۰۰ تای ان یک کلمه خاص (مثلاً است) وجود داشته باشد حاصل لگاریتم ۱۰۰۰ تقسیم بر ۱۰۰۰ میشود صفر. یعنی حتماً این کلمه جز کلمات متداول بوده و باید ضریب صفر بگیرد ولی اگر تکرار در ۵۰۰ متن اتفاق افتاده باشد میشود لگاریتم ۲ که حاصل ۱ است ضریب ۱ میگیرد. هر چفدر متونی که کلمه در ان تکرار شده باشد بیشتر باشد وزن idf کوچکتر میشود؛ و چون مکن است اصلاً تکرار نشده باشد و مخرج صفر شود در مخرج +۱ اضافه میشود.
idf (t,D)=log〖(D/(1+{dϵD:tϵd}))〗
با این توضیحات میزان tfidf به صورت زیر محاسبه میشود:
tfidf(t,d,D)=tf(t,d)*idf(t,D)