کد استفاده از کتابخانه های ابزارهای پردازش متن فارسی (نرمال سازی، تشخیص جملات، تشخیص کلمات، حذف ایست واژه ها و ریشه یابی)
حذف کننده کلمات ایست (Stopword Remover)
در این ابزار، کلمات کم اهمیت تر و یا ایست واژه ها در صورت تایید کاربر از متون مورد پردازش، حذف میگردند. ایست واژه ها لغاتی پرکاربرد و اغلب کم اهمیتی هستند که هنگام کار با متن به وفور با آنها برخورد میشود مثل “اگر“، “و“، “که” و غیره. در نگاه اولیه کلمات ربط و تعریف، ایست واژه به نظر می آیند؛ در عین حال بسیاری از افعال، افعال کمکی، اسم ها، قیدها و صفات نیز ایست واژه شناخته شده اند. این کلمات علی رغم اینکه بسیار استفاده می شوند، اما از لحاظ معنایی دارای اهمیت کمی بوده و بهمین دلیل عموما در فعالیتهای مربوط به حوزه پردازش زبان طبیعی که با حجم انبوهی از داده ها روبهرو هستیم، در فاز پیش پردازش حذف میشوند. برای حذف این کلمات عموما لیستی از این کلمات از پیش تهیه میشود و سپس در صورت رخداد این کلمات در متن، از سند حذف میشوند. در اغلب کاربردهای متن، حذف این کلمات نتایج پردازش را بهبود میدهد. علاوه بر این از آنجا که بیشتر کاربردهای پردازش متن با حجم عظیمی از داده ها رو به رو هستند، حذف این کلمات سبب کاهش بار محاسبات و افزایش سرعت خواهد شد. برای زبان فارسی بایستی لیست این واژه ها با دقت فراوانی تهیه گردد.
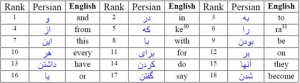
ایست لیست ها یک فایل محتوی تعدادی کلمه پرتکرار است که شامل عمومیترین افعال، ضمایر، قیدها، حروف ربط و حروف اضافه میباشد.
کد استفاده از کتابخانه های ابزارهای پردازش متن فارسی (نرمال سازی، تشخیص جملات، تشخیص کلمات، حذف ایست واژه ها و ریشه یابی)
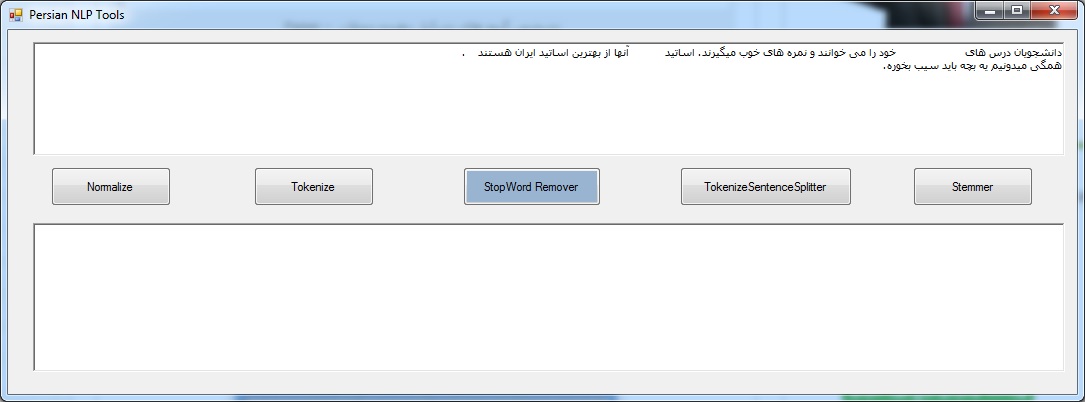
در این کد که به زبان سی شارپ نوشته شده است چگونگی استفاده از کتابخانه های ابزارهای پردازش متن فارسی زیر آورده شده است:
– نرمالسازی متون فارسی – Normalizer
– تشخیص کلمات – Tokenizer
– حذف ایست واژه ها – Stop Word Remover
– تشخیص جملات – Sentence Spliter
– ریشه یابی کلمات – Stemmer
فایل فشرده حاوی کد زبان سی شارپ به همراه کتابخانه های مورد نظر بعلاوه لیست ایست واژه های زبان فارسی
FarsiStopWords.txt




 فروش مستقیم زعفران
فروش مستقیم زعفران 






